
Assistant Professor at University of A Coruña
Regards!
I am Jonatan Enes, a Computer Engineer who likes frugality, ecologism, and to tinker with system's performance, so maybe everything is related!!
Currently I am working as a researcher and an assistant teacher in the University of A Coruña (UDC), in Spain.
2016 - 2020
University of A Coruña
Finally, I returned to Coruña where I got my PhD, which focused on resource (CPU, memory, disk, network and energy) analysis on Big Data infrastructure and applications, as well as the serverless paradigm for resource management, all of this using containers as the infrastructure virtualization technology.
2015 - 2016
University of Santiago de Compostela
After I got my bachelor's degree, I decided to move to the near city of Santiago de Compostela. There I got my master's degree, which mainly revolved both around Big Data technologies and infrastructure, as well as Machine Learning.
2011 - 2015
University of A Coruña
After finishing high school I moved to A Coruña, in the northwest of Spain, to continue with my college education. In Coruña I studied a 4-year degree in Computer Science with a specialization in Computer Engineering.
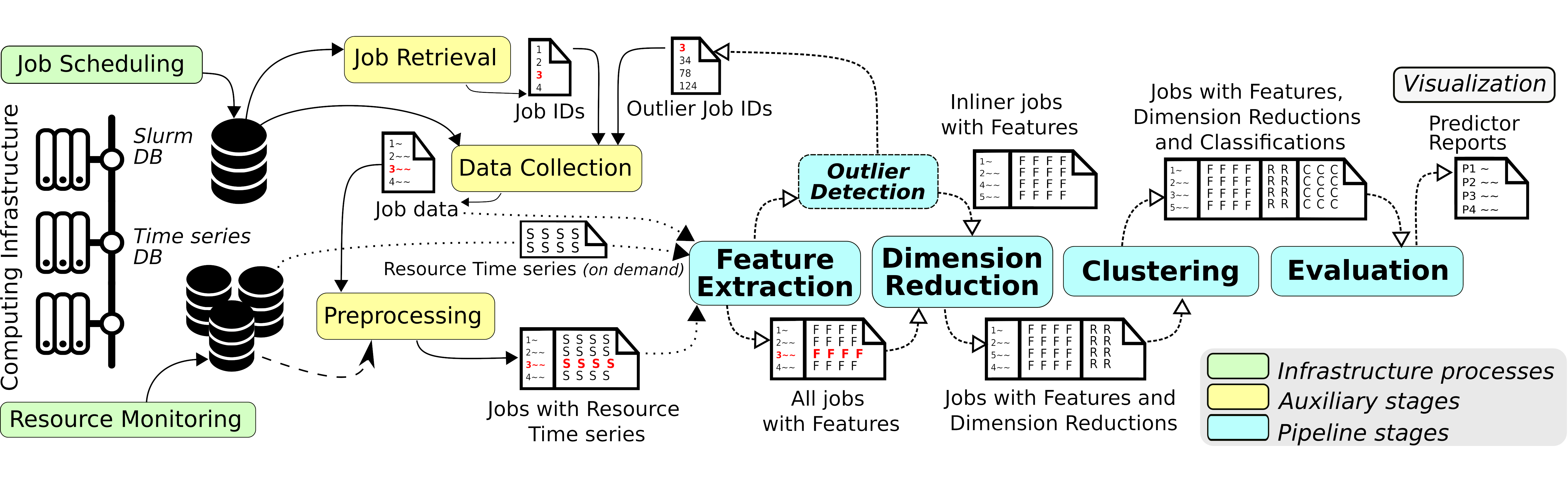
Clustering of resource time series from a Supercomputer (2022)
In order to better understand how jobs are executed on a supercomputer, and if such jobs can be grouped in some way to extract valuable information, we developed a pipeline architecture that combines Big Data and Machine Learning. More specifically, this pipeline processes resource time series (e.g., User CPU or Cached memory) to extract features, which are then used to group the jobs in an unsupervised way through various dimension reduction and clustering techniques. The heavy bulk of this processing is carried out using a Big Data cluster and Spark.
Additionally, jobs are not only grouped, but also those which do not fit in any group are detected and isolated, thus being considered potential anomalies. These anomalies can be useful to users or system administrators.
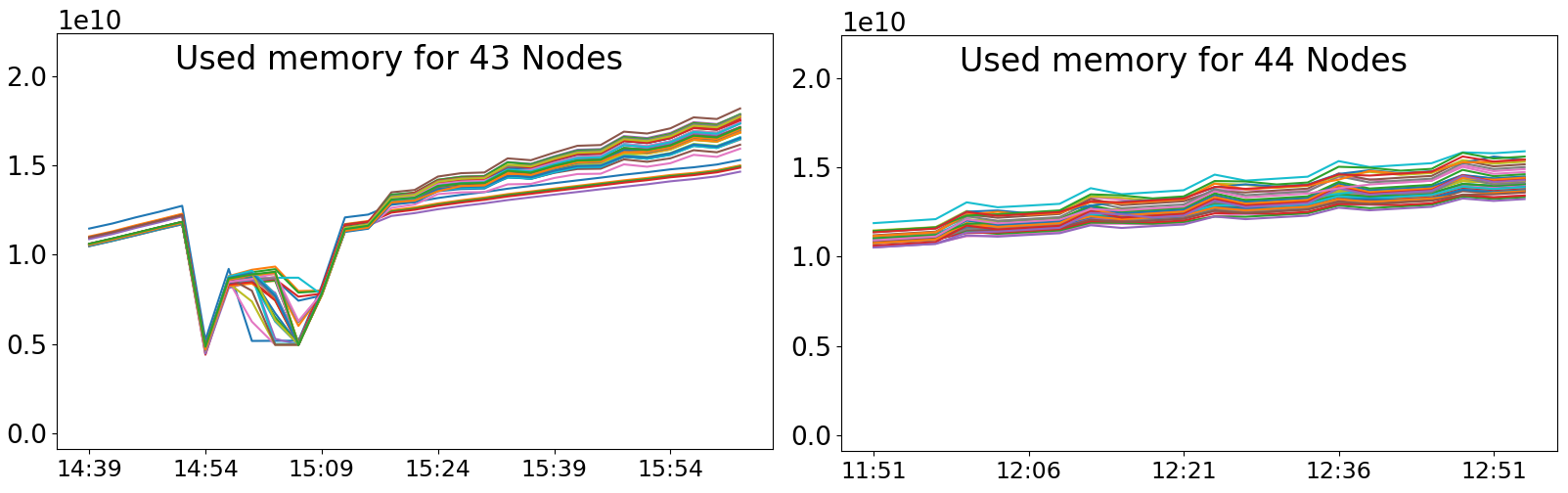
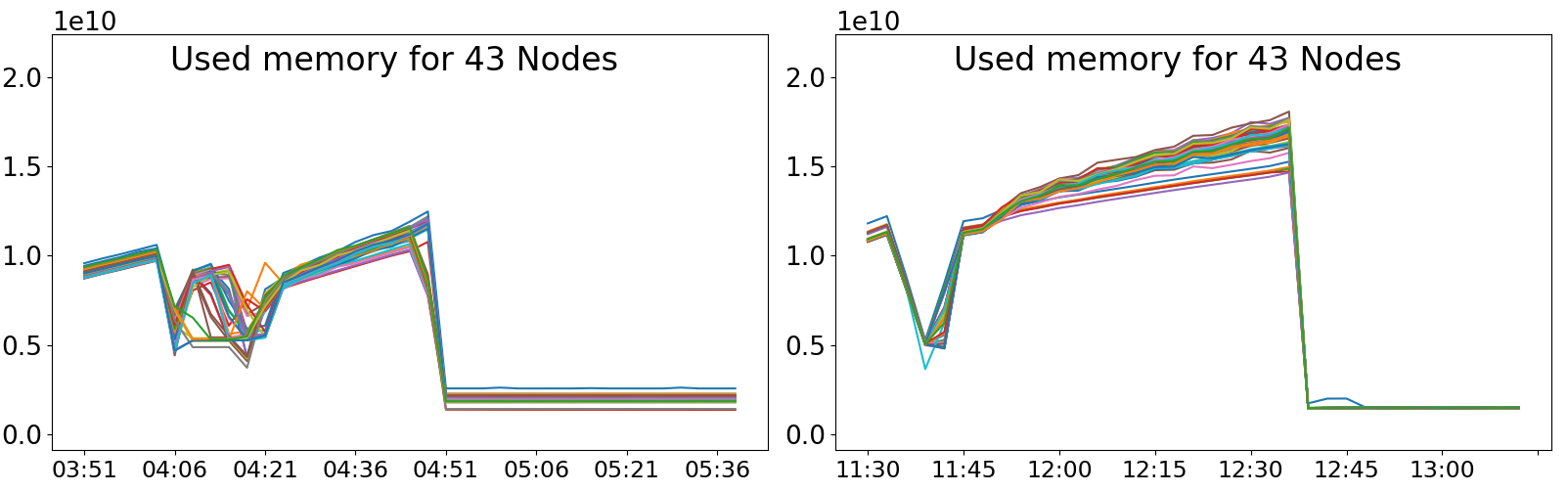
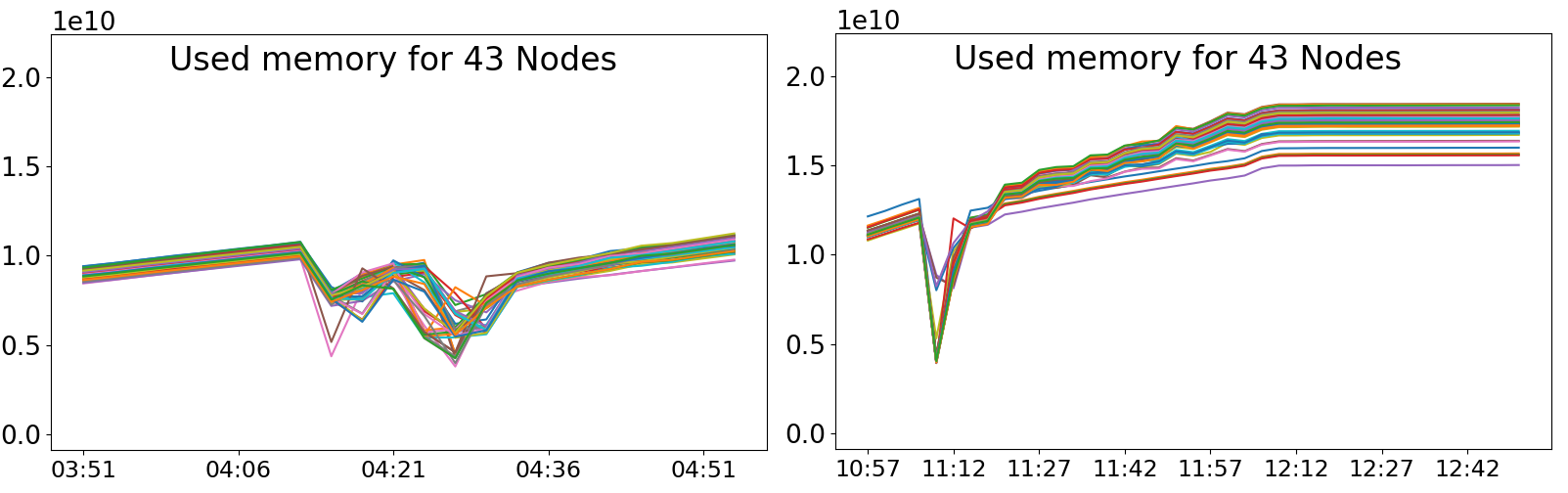
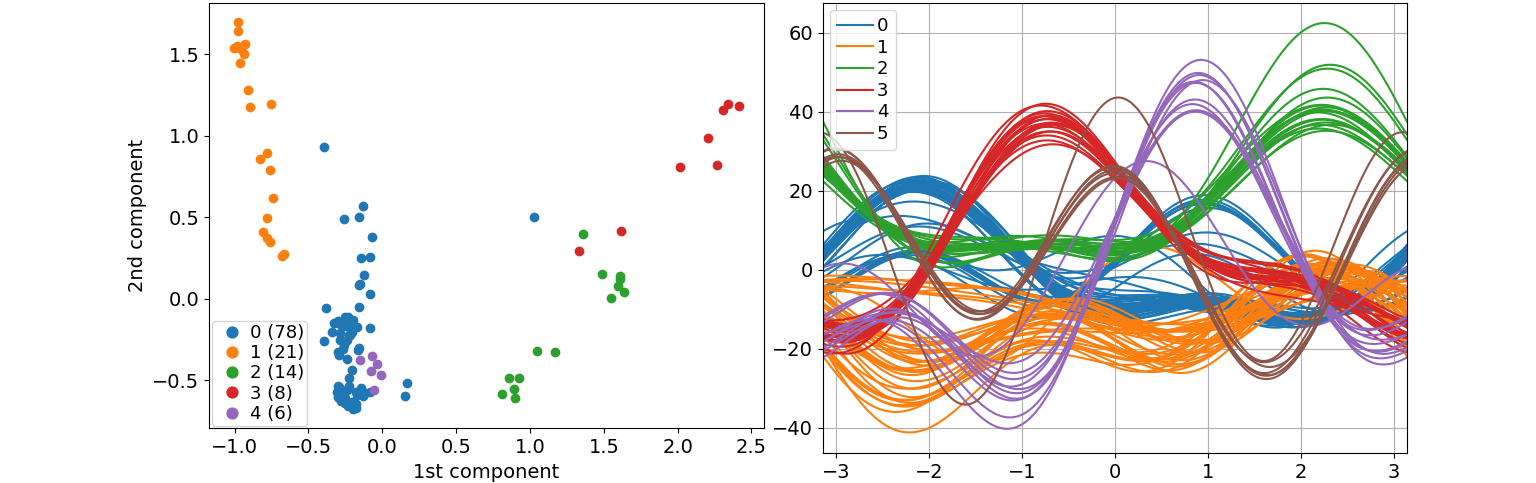
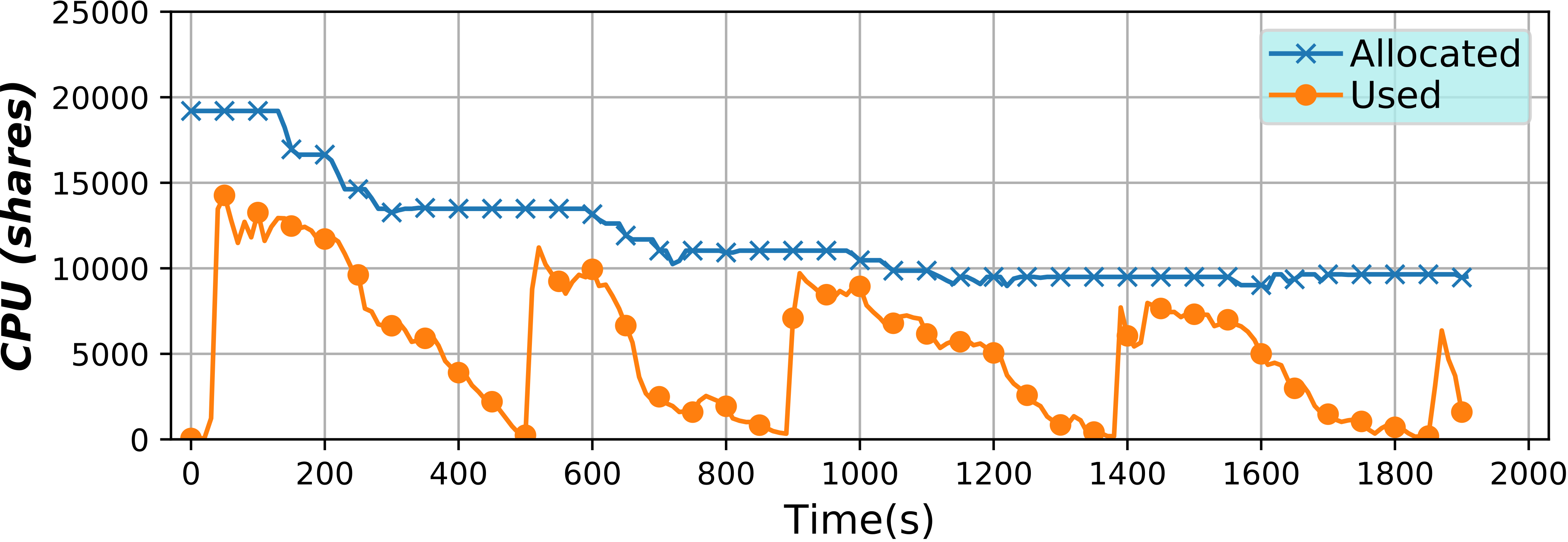
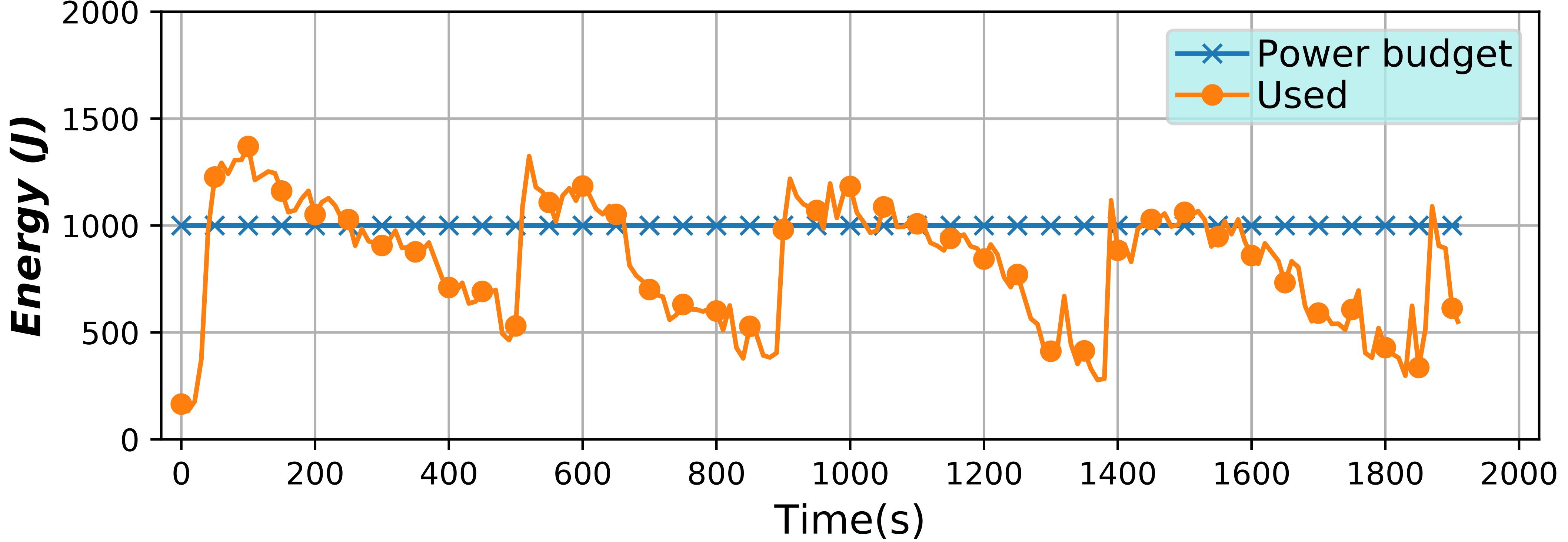
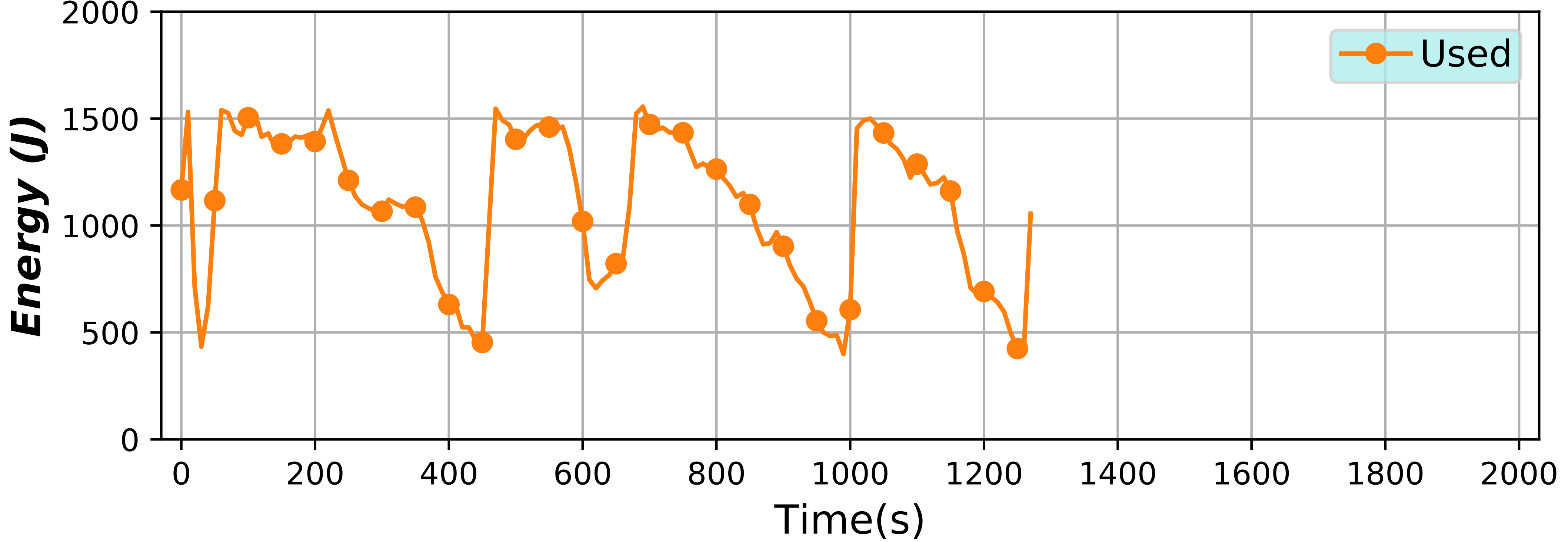
Energy capping of containers and applications (2019)
In this project, a special usage case is studied where the energy of containers is monitored and controlled with the objective of being able to set an energy limit and have it enforced. In this experimental environment, energy is considered just as another accountable resource, alongside CPU or memory. This also implies that it can be shared between different containers, applications or users.
This environment is created with the combination of several tools. For the monitoring of the resources and the processing and handling of the time series, BDWatchdog is used. The CPU scaling to implement the energy limitation and enforcement is carried out by using the Serverless Containers framework. Finally, lying at the core of this study is the energy monitoring, which is provided by the PowerAPI framework developed at the Spirals group of INRIA Lille – Nord Europe. You can check out their tool here.
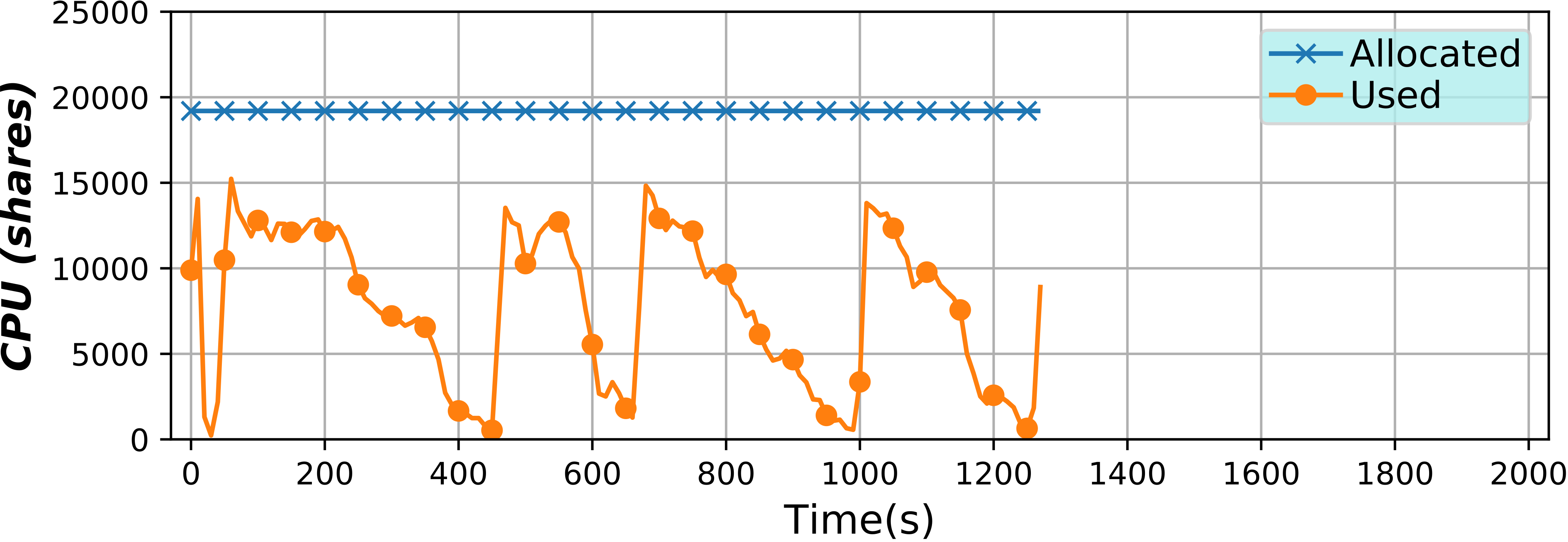
Serverless Containers framework (2018)
This framework has been developed to implement serverless computing, that is, to only allocate the resources an application needs at any moment, but for containers. By varying such resources it is possible to optimize them, potentially lowering billing costs, or improving their usage efficiency.
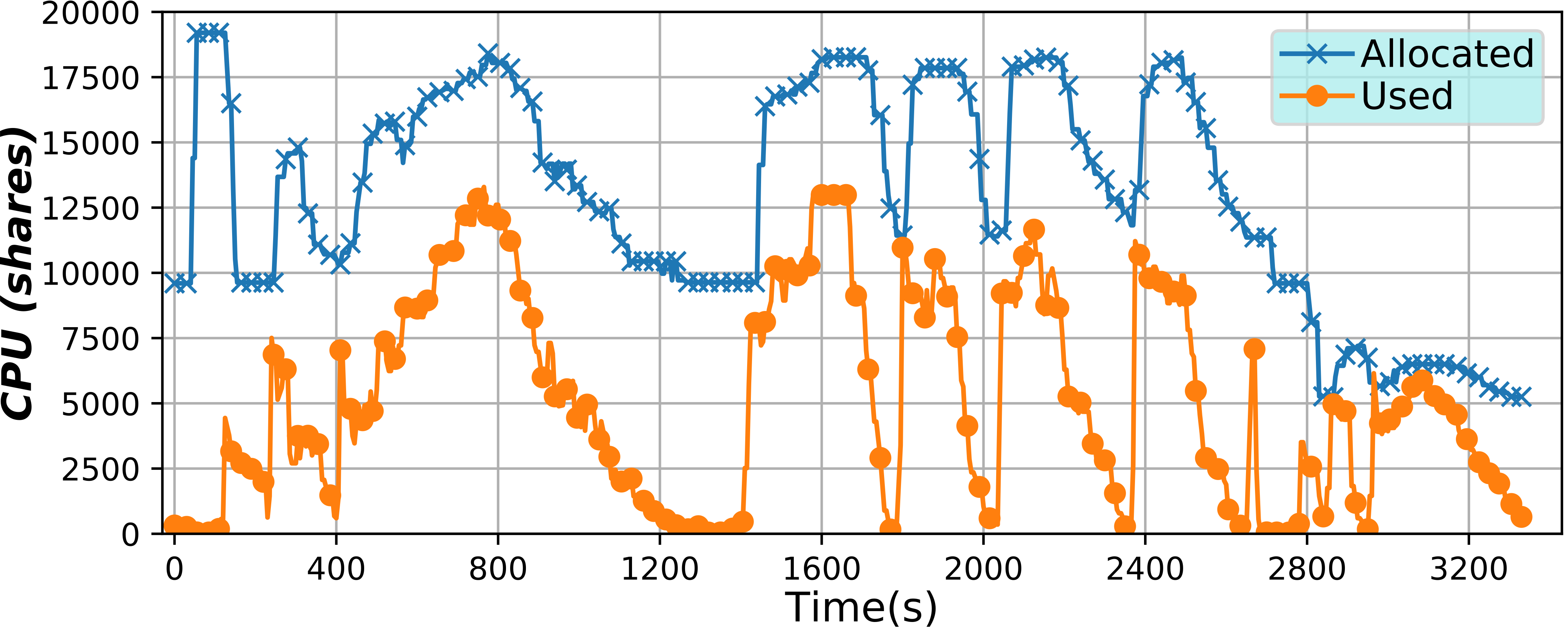
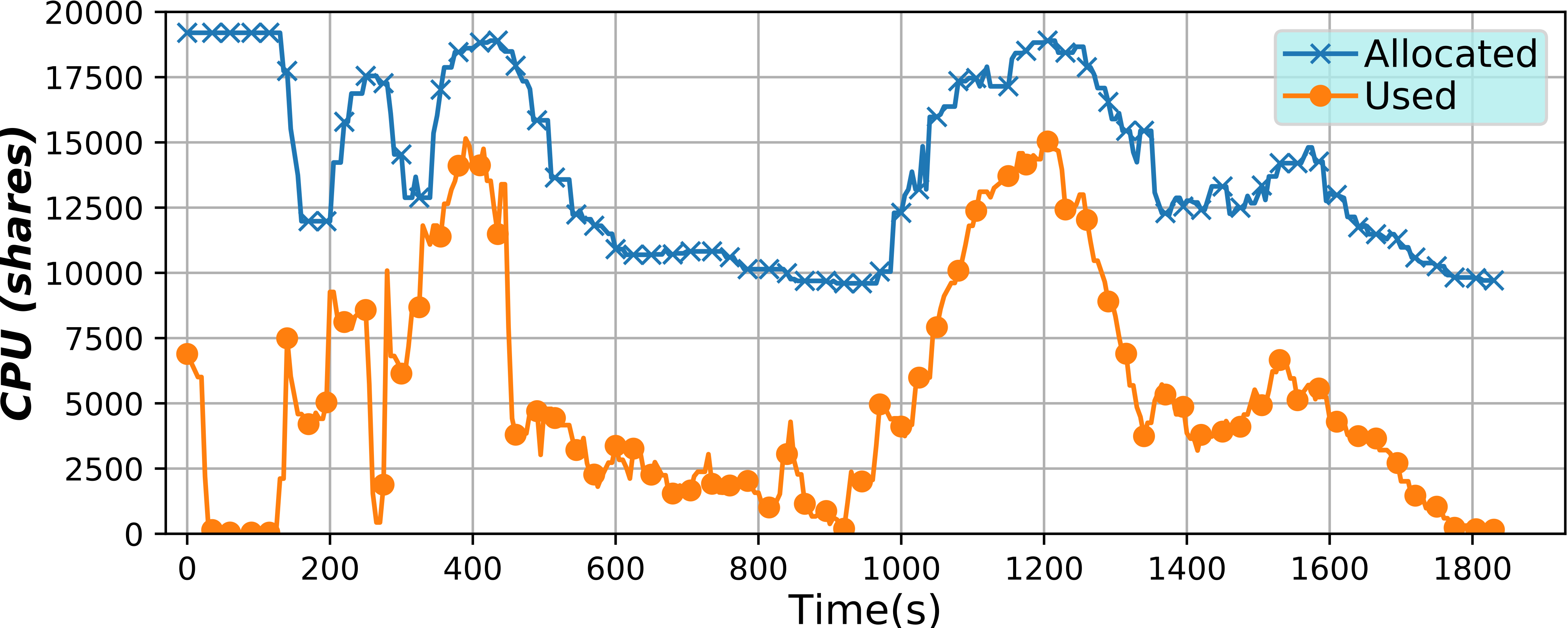
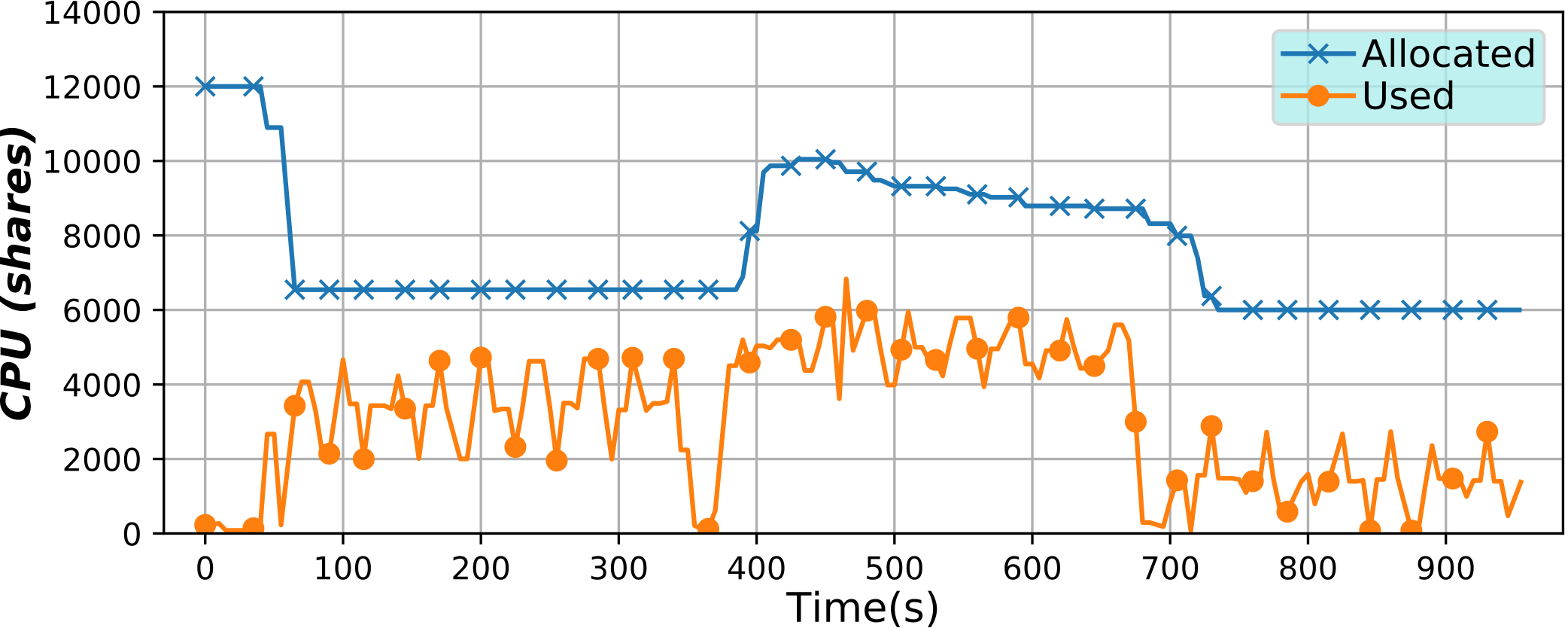
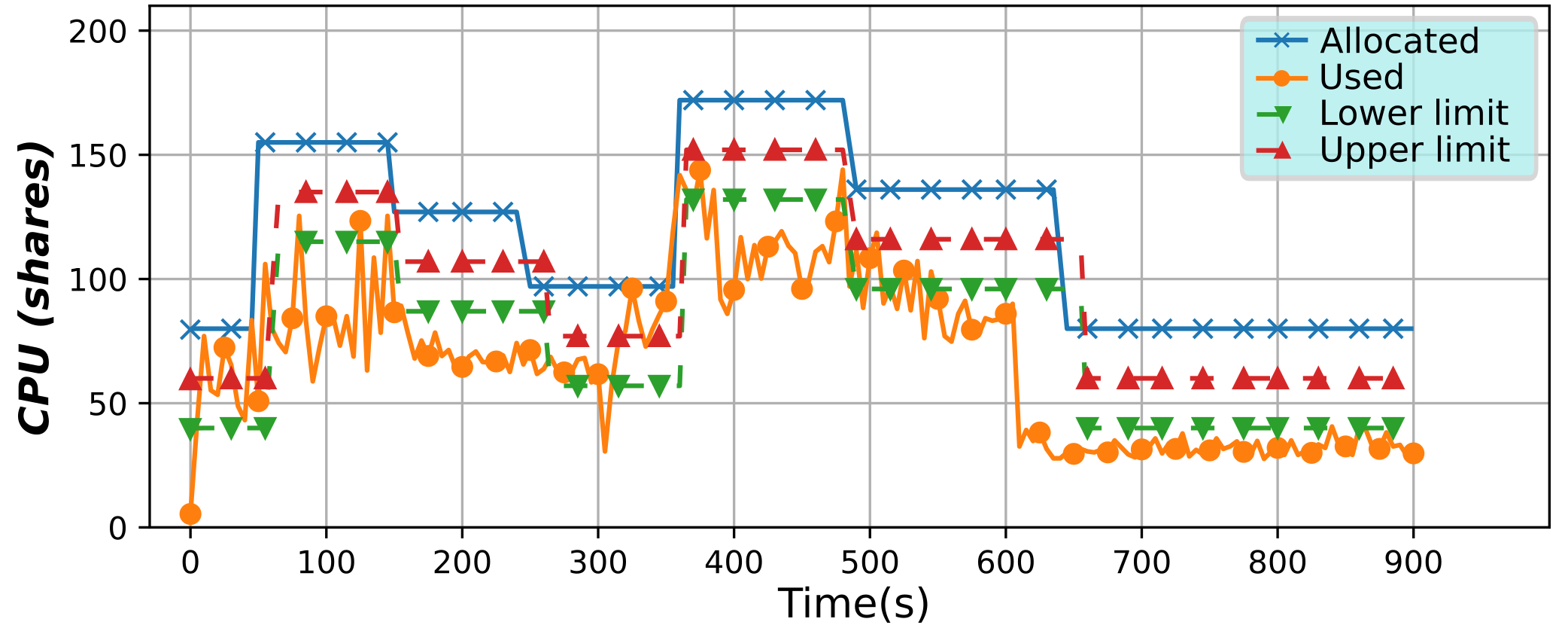
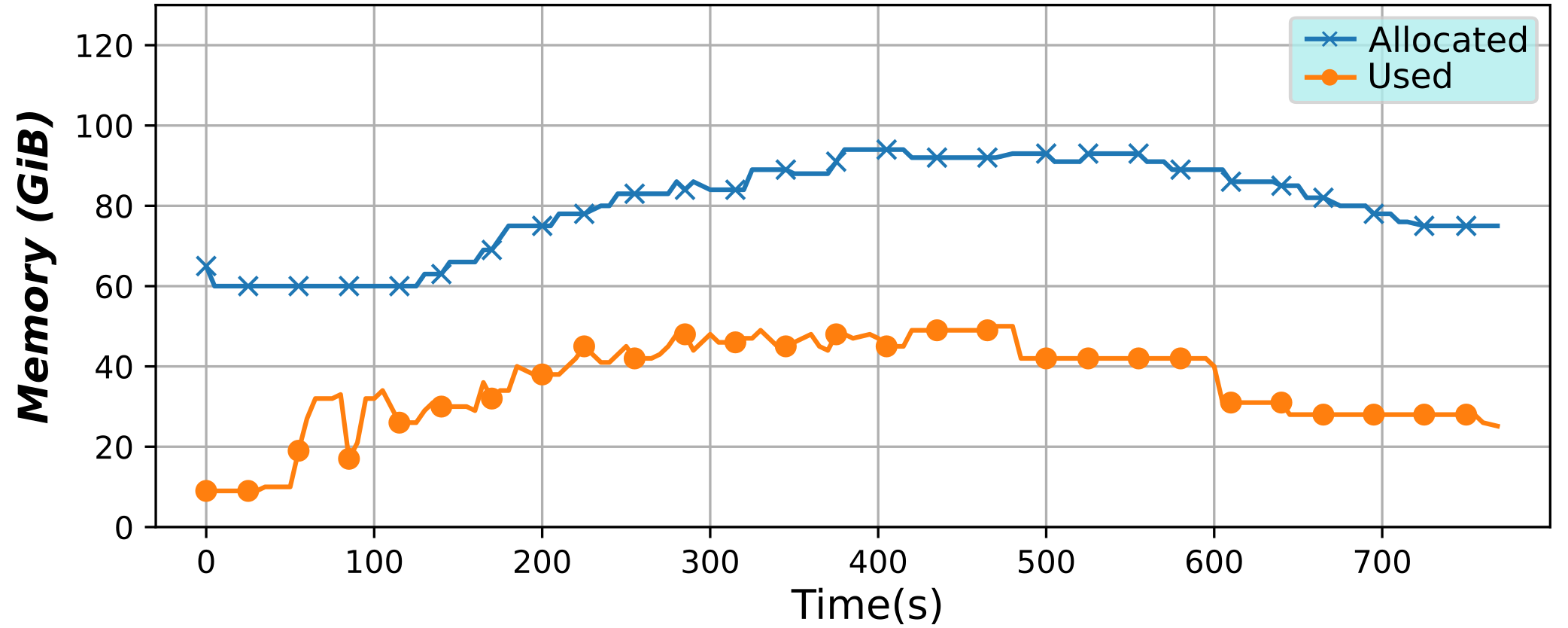
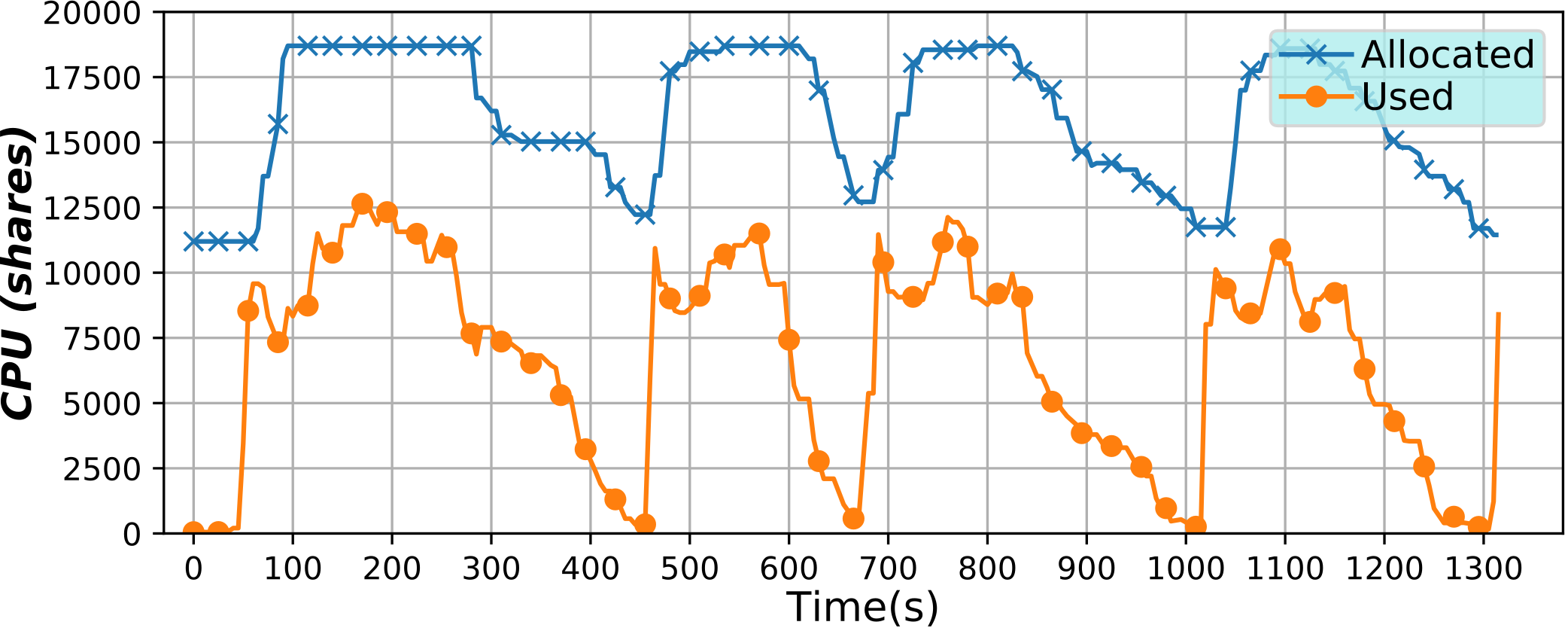
Also interestingly, the user is given a virtual environment that is really close to a virtual machine or a Cloud instance. More on the technical side, this tools continuously changes the resource limits applied to a container, or a group of containers, in real time and in an automatic way without the need for any user intervention. To do so, a microservice architecture has been used, along with monitoring with BDWatchdog.
Learn more...BDWatchdog, monitoring and profiling framework (2017)
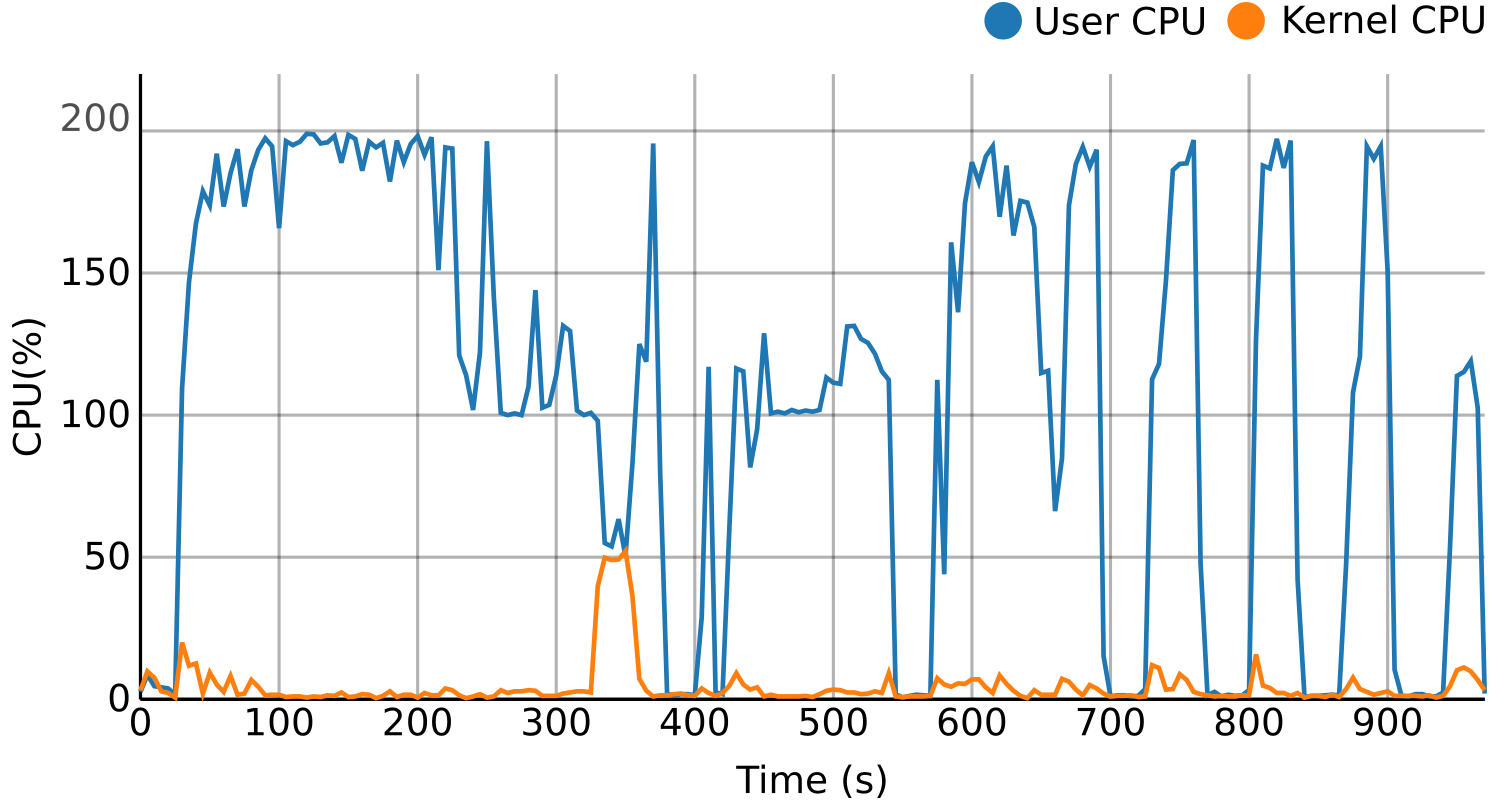
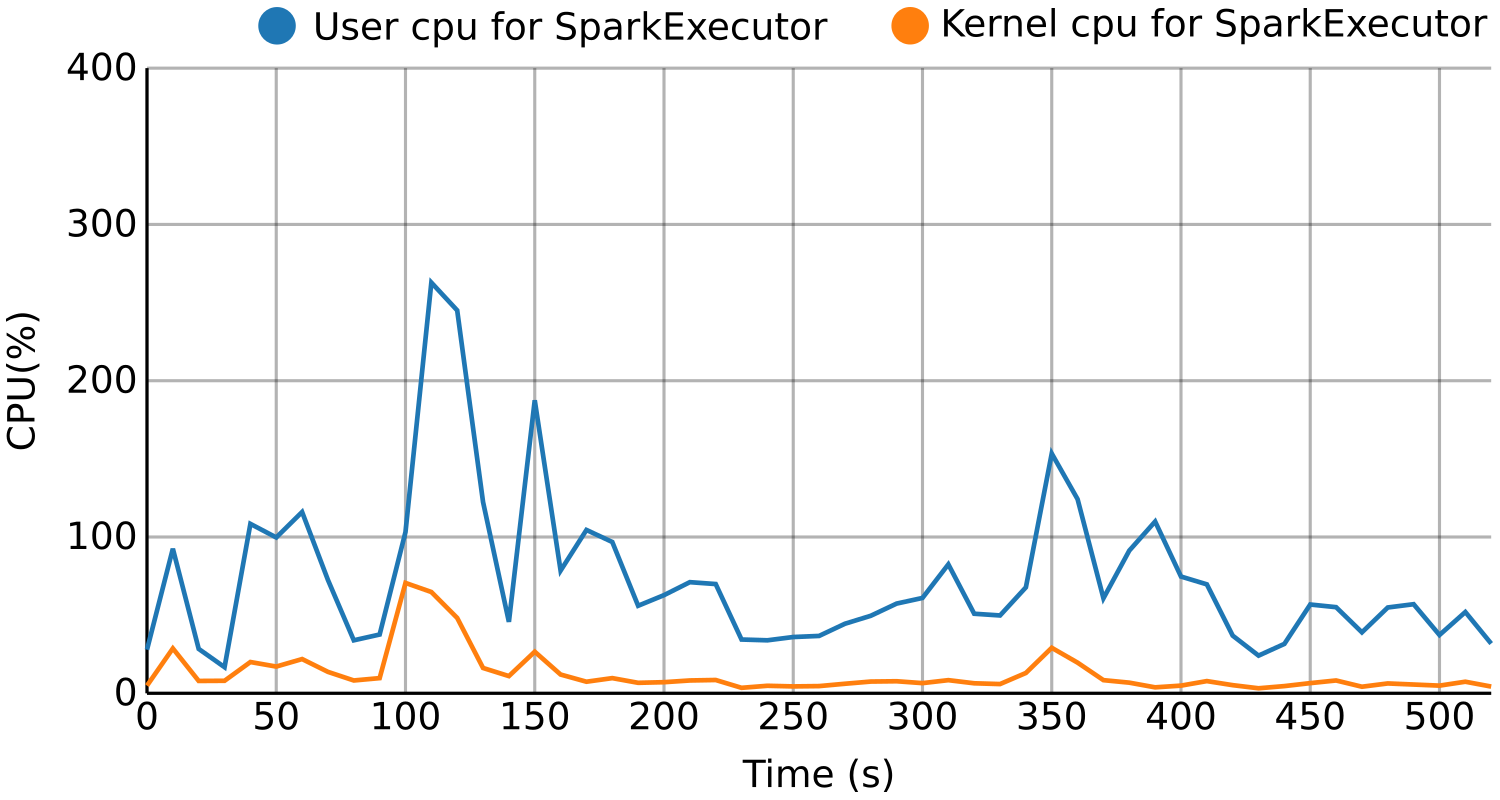
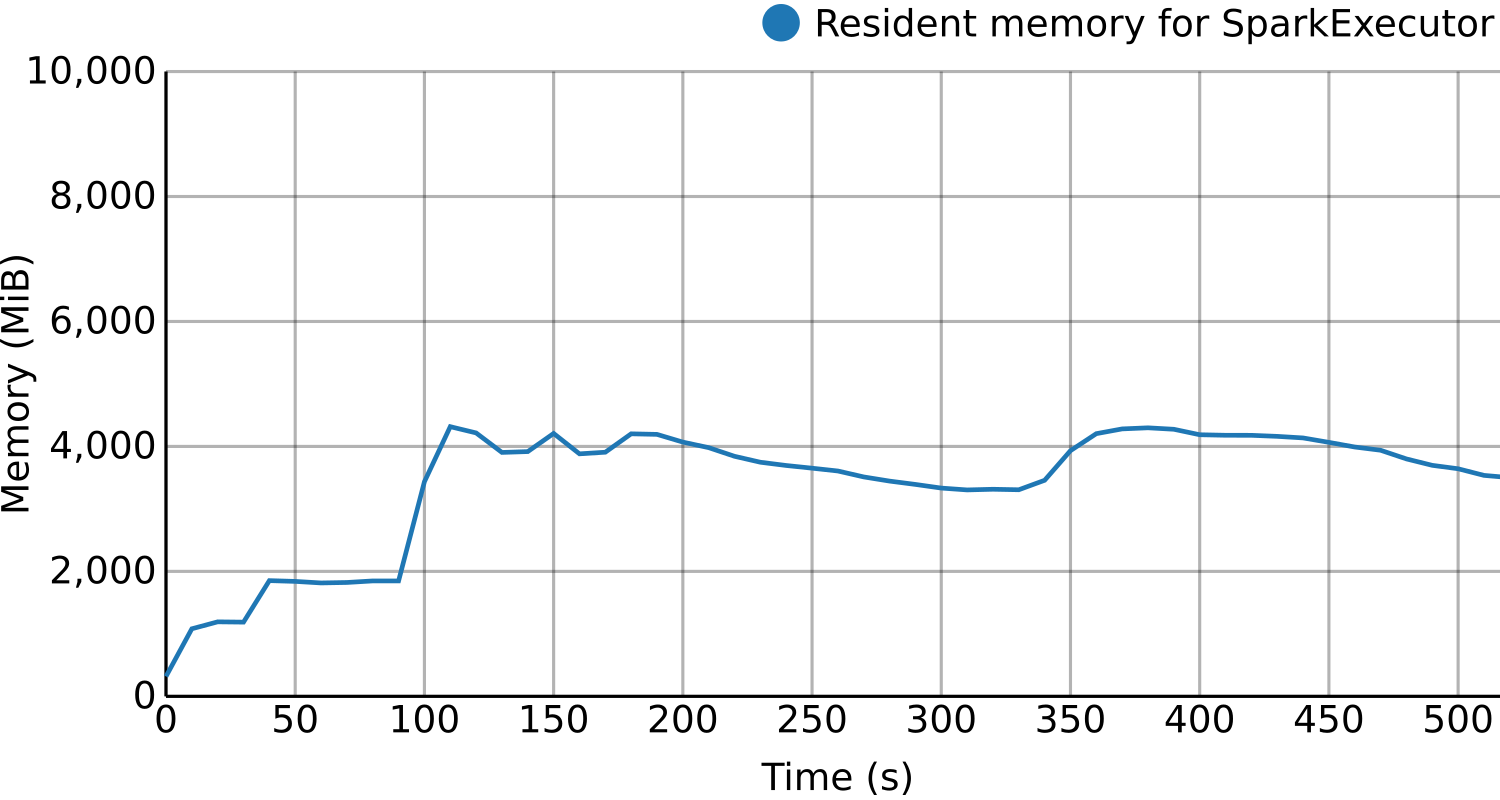
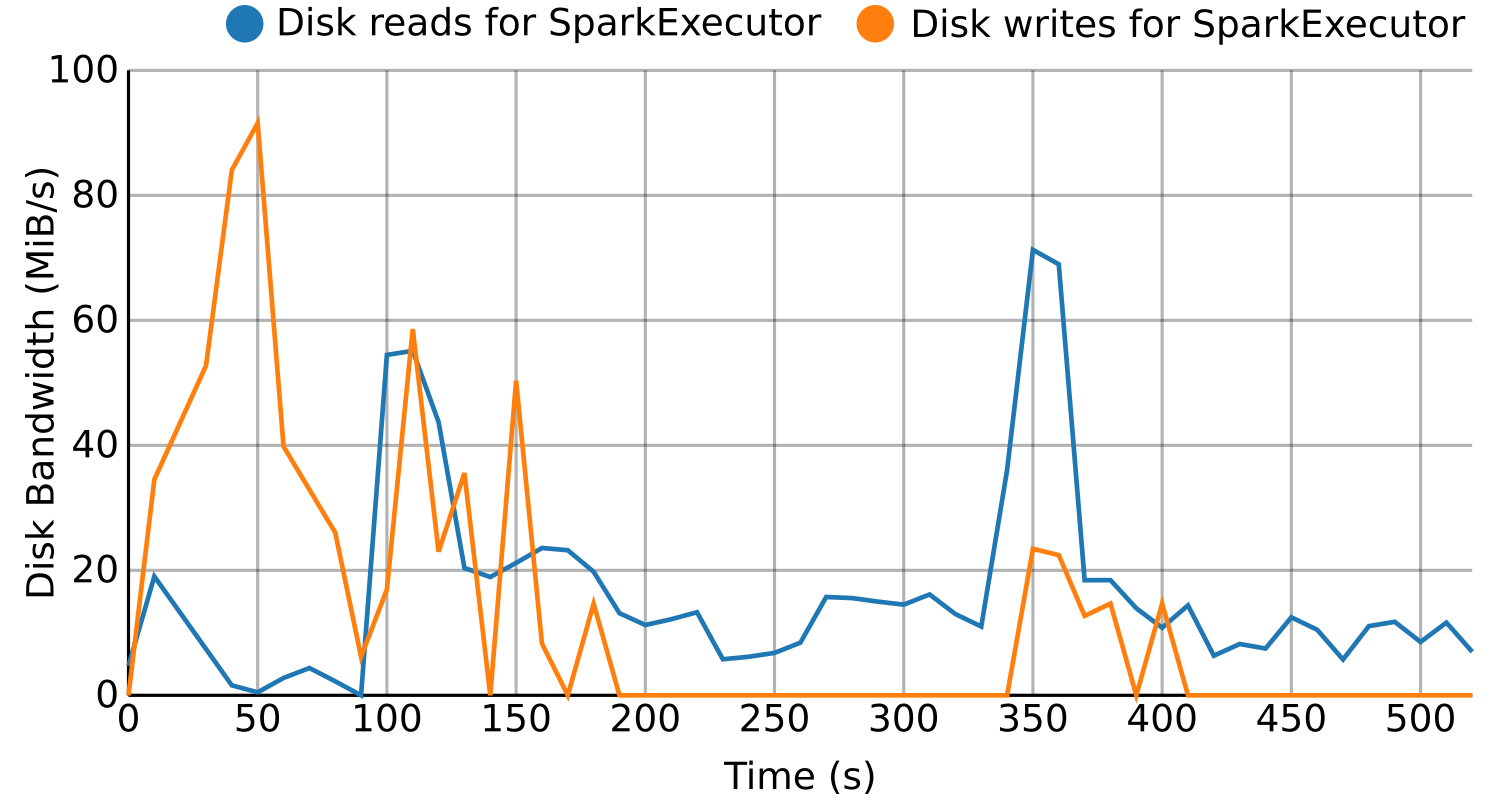
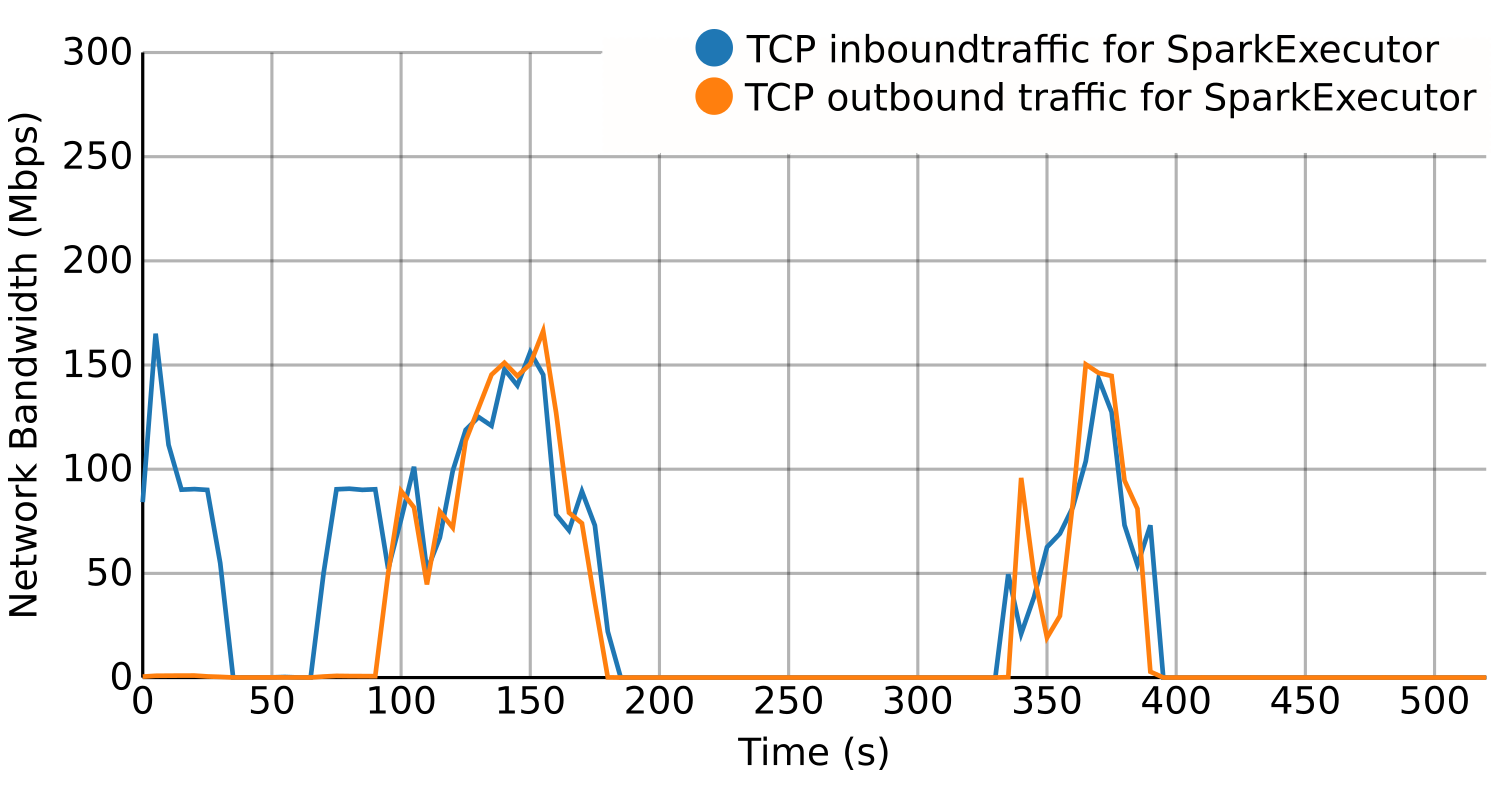

BDWatchdog is a framework to provide both resource monitoring (CPU, memory, disk and network), as well as profiling information. All of this information is generated, processed and stored in real time by using a time series database (OpenTSDB) for monitoring and a document-based database (mongodb) for profiling. The architecture used is also scalable to support large clusters. The end result of using this framework is two-fold:
- Per-process resource time series detailing how such resources were used during execution, with the possibility of filtering by using tags like host, command, and performing aggregation operations like summatory o average.
- Interactive profiling flame graphs showing the percentage of time spent in a specific Java class, being subsequently subdivided across its calls.
Big Data PaaS with disk-aware scheduling (2016)
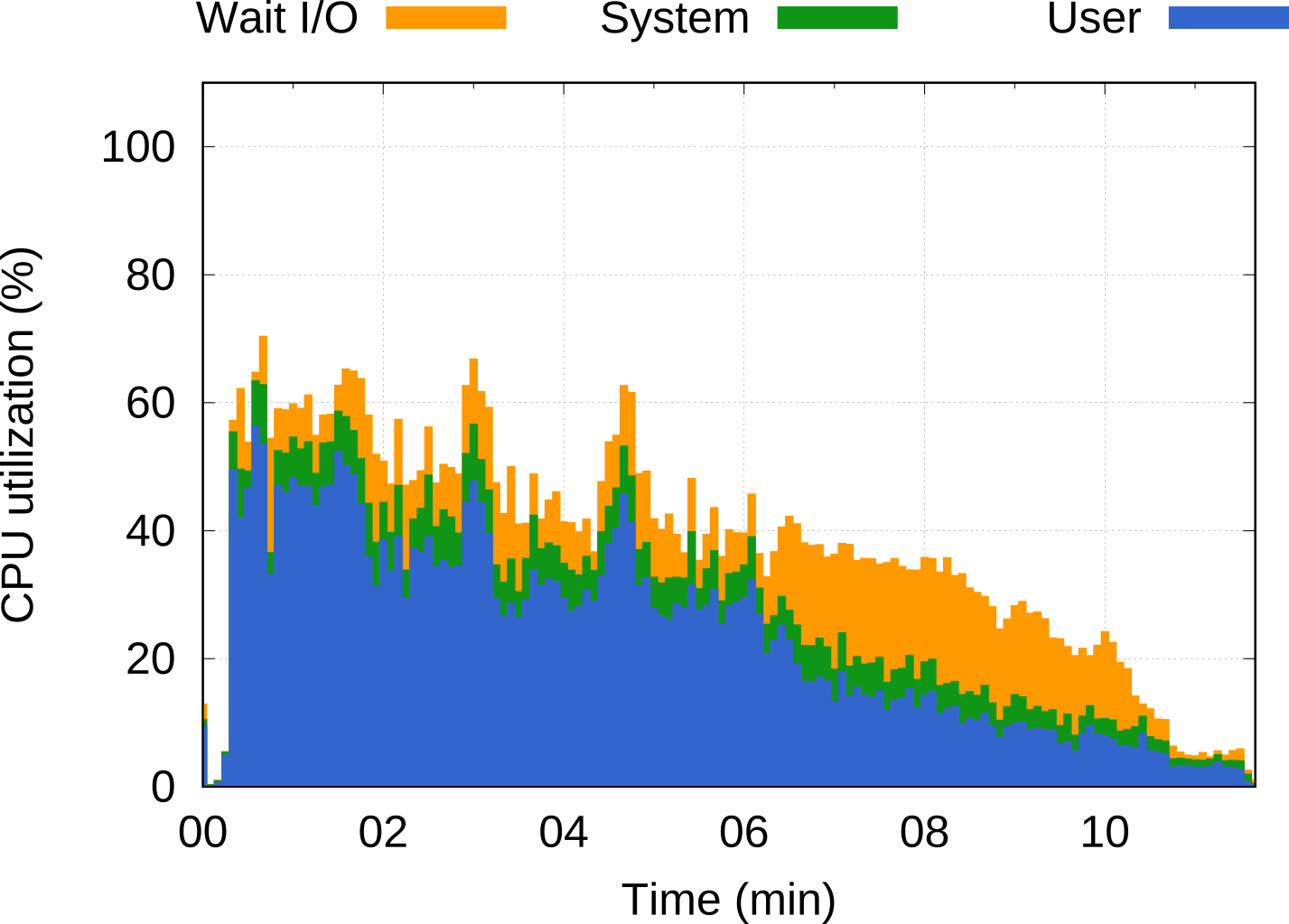
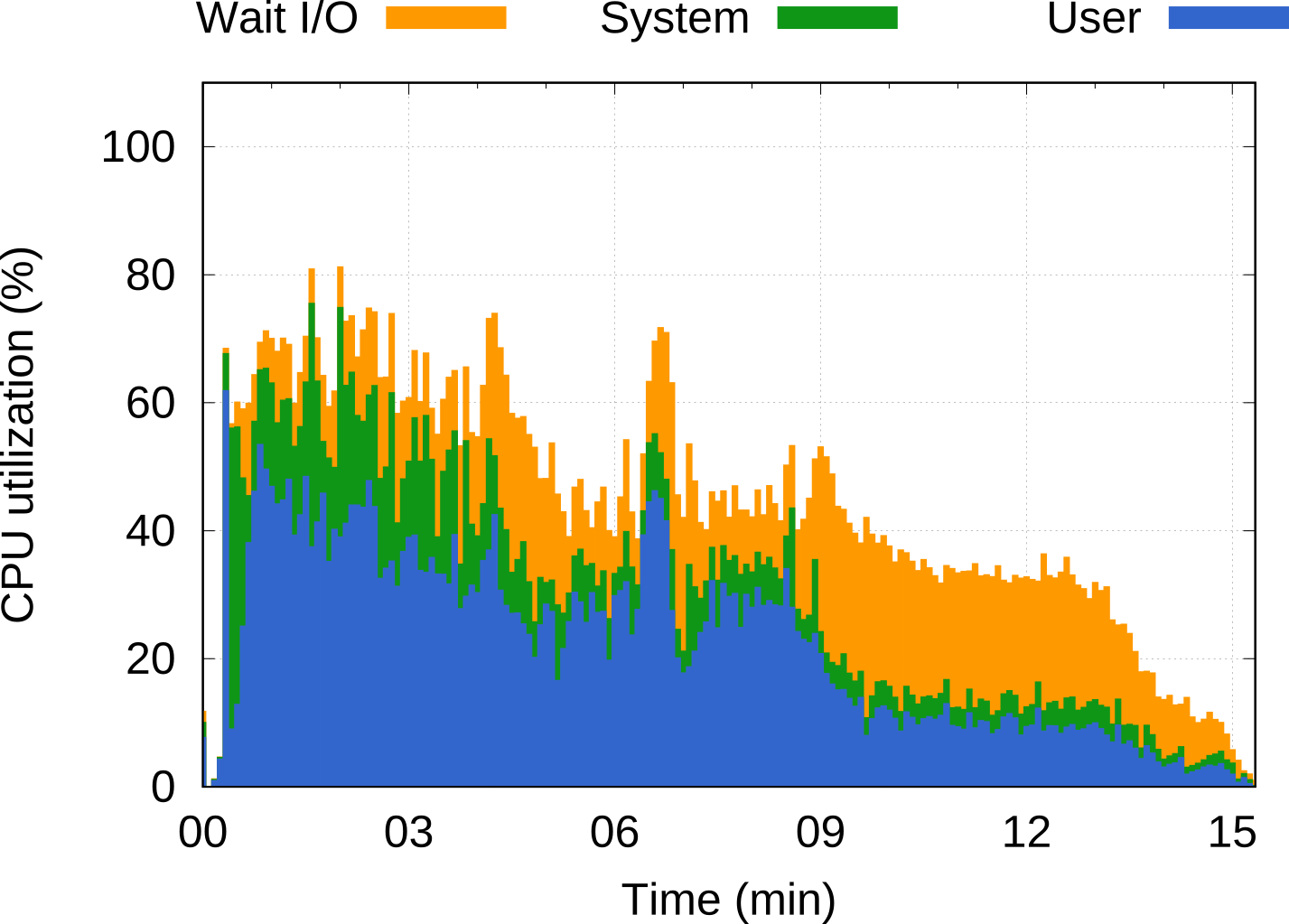
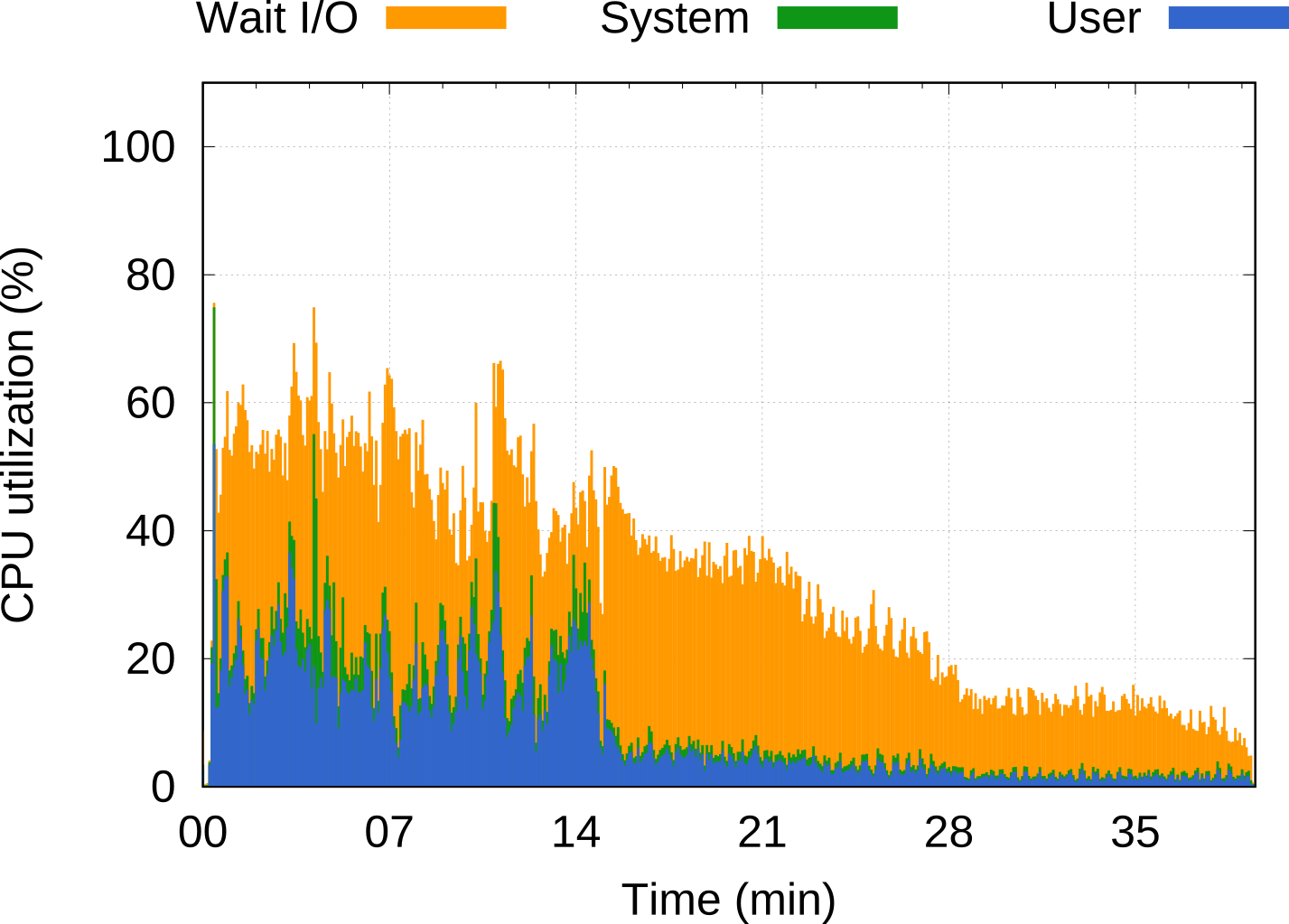
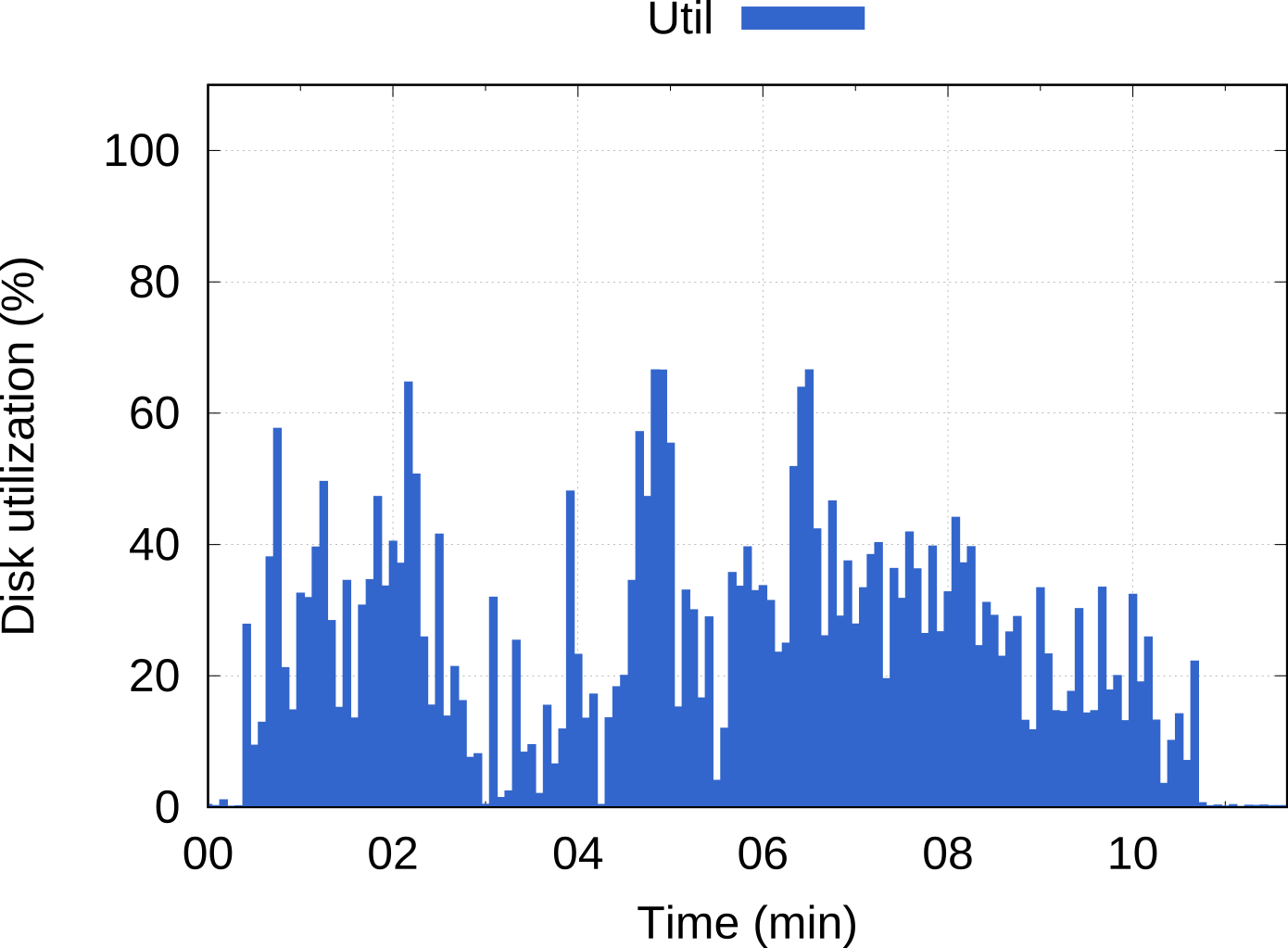
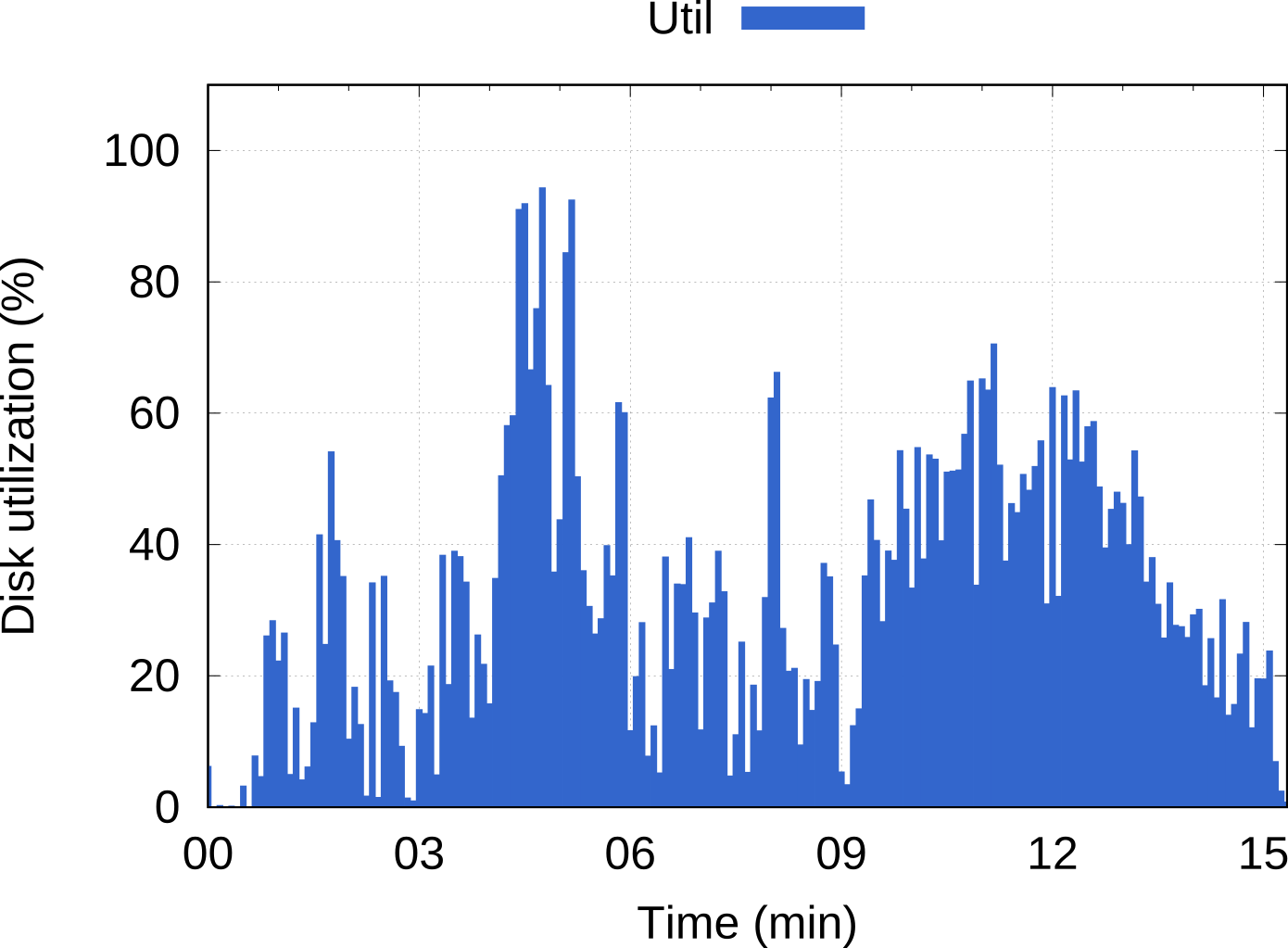
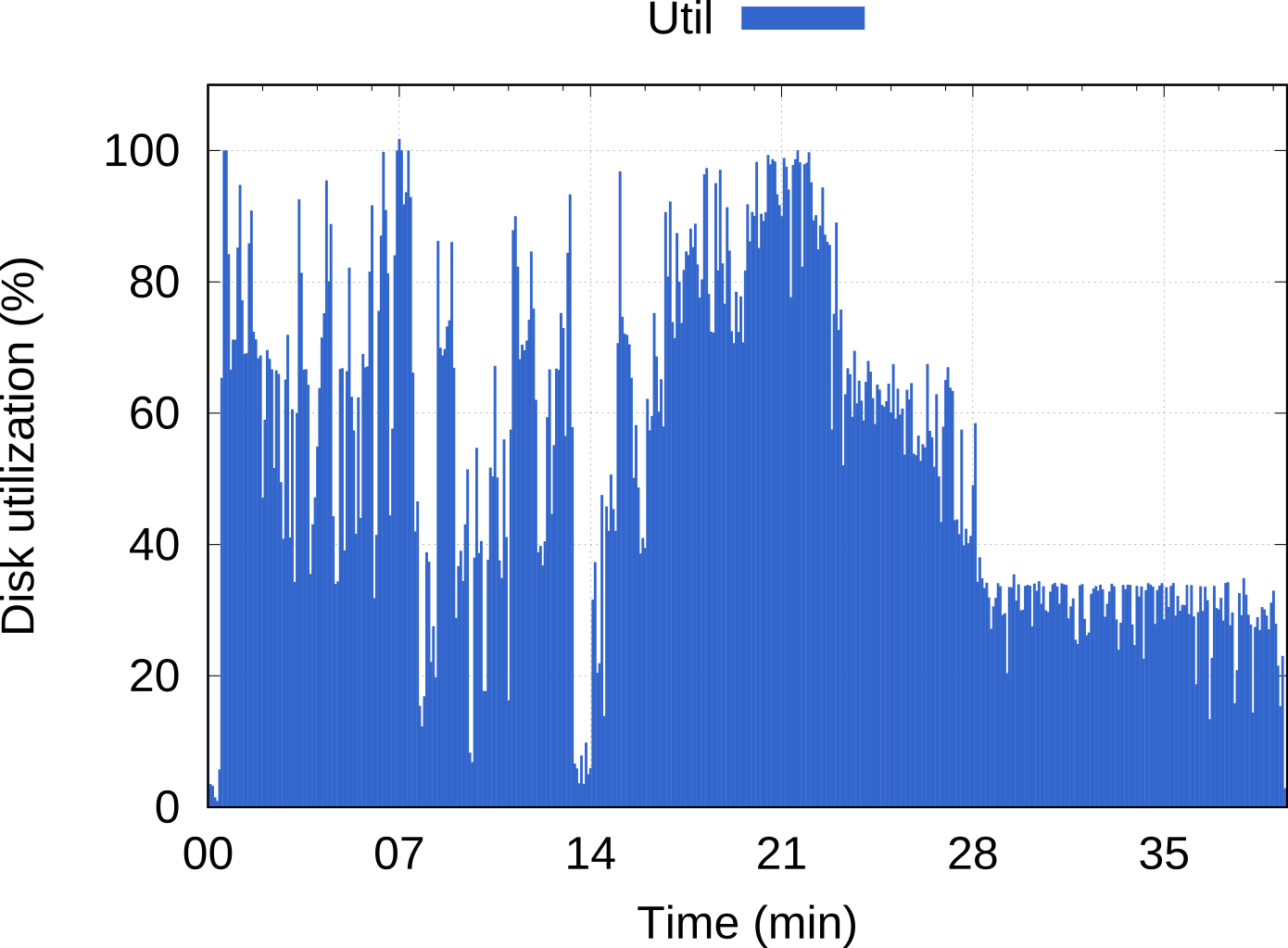
This platform was designed from the start with novel concepts to specifically enhance Big Data workloads in two ways:
- Docker containers instead of virtual machines backed by hypervisors.
- A disk-aware capability implemented on Mesos as the resource scheduler, giving users the option of choosing disks as dedicated resources in the same way as CPUs and memory.
Conference paper in:
IEEE Cluster 2024
24-27 September
Kobe, Japan
Tomé Maseda, Jonatan Enes, Roberto R. Expósito, Juan Touriño in IEEE International Conference on Cluster Computing, CLUSTER 2024, Kobe, Japan, 2024, pp. 97–107. (link)
Full length article in:
Future Generation Computer Systems (FGCS)
2024
Óscar Castellanos-Rodrı́guez, Roberto R. Expósito, Jonatan Enes, Guillermo López Taboada, Juan Touriño, Future Generation Computer Systems, 155 (2024), 256–271, (link)
Full length article in:
Information Fusion
2023
Jonatan Enes, Roberto R. Expósito, José Fuentes, Javier L. Cacheiro, Juan Touriño, Information Fusion, 93 (2023) 1-20. (link)
Conference paper in:
IEEE Cluster 2020
14-17 September
Kobe, Japan
Jonatan Enes, Guillaume Fieni, Roberto R. Expósito, Romain Rouvoy, Juan Touriño in IEEE International Conference on Cluster Computing, CLUSTER 2020, Kobe, Japan, 2020, pp. 281–287. (link)
Full length article in:
Future Generation Computer Systems (FGCS)
2020
Jonatan Enes, Roberto R. Expósito, Juan Touriño, Future Generation Computer Systems 105 (2020) 361-379. (link)
Full length article in:
Future Generation Computer Systems (FGCS)
2018
Jonatan Enes, Roberto R. Expósito, Juan Touriño, Future Generation Computer Systems 87 (2018) 420–437. (link)
Full length article in:
Journal of Grid Computing
2018
Jonatan Enes, Javier L. Cacheiro, Roberto R. Expósito, Juan Touriño, Journal of Grid Computing 16 (4) (2018) 587–605. (link)
Full length article in:
Future Generation Computer Systems (FGCS)
2018
Jorge Veiga, Jonatan Enes, Roberto R. Expósito, Juan Touriño, Future Generation Computer Systems 86 (2018) 565–581. (link)
2021 - current
Universidade da Coruña
I am currently hired as a full time teacher in Universidade da Coruña, you can check out the subjects I am part of below.
I have currently taught over 1.300 hours and supervised several subjects. Additionally, I have implemented from the ground up two related new subjects that aim at teaching parallelism to students from various areas of engineering from a new perspective introducing the classic methodologies and techniques but using new frameworks and technologies.
April 2019 - July 2019
Inria Lille, France
For 3 months I stayed at Lille to work on the Spirals group in the integration of their energy measuring PowerAPI tool and both of my frameworks, BDWatchdog and the Serverless containers. The result of this integration, an environment where energy is treated as just another resource and thus, it can be accountable and shareable, is described above.
July 2015 - June 2016
For a year I worked in the Galicia Supercomputer Center (CESGA) developing a novel PaaS where Big Data applications can be easily deployed by users.
In this platform applications also benefit from specific data-processing enhancements such as lighter virtualization using Docker containers and direct and local disk access by including whole disks as a configurable resource along CPU and memory.
Sept 2024 - current
For the study and implementation of a multitude of tasks involving energy in container-based environments, such as monitoring, analysis, modelling and prediction. Such environments will also be composed of multiple containers which run distributed and cluster-based applications.
All these data will then be used for an active energy management, including techniques of power capping, but also power budgets and power distribution and balancing between different applications and users.
Link to his webpageComputer Engineering Degree
-
Estructura de Computadores
- Computer structure and engineering
- 2017 - 2019 🡆 2 academic years
-
Fundamentos de los Computadores
- Basics of computer structure and engineering
- 2018 - 2021 🡆 3 academic years
-
Concurrencia y Paralelismo
- Concurrent and parallel programming
- 2020 - 2024 🡆 4 academic years
-
Calidad en la Gestión TIC
- Quality management for IT
- 2020 - 2026 🡆 6 academic years
- Single teacher and supervisor of the subject
Data Science and Engineering Degree
-
Procesamiento Paralelo
- Parallel processing
- 2021 - 2026 🡆 5 academic years
- Supervisor of the subject
- Newly implemented subject
Artificial Intelligence Degree
-
Computación Concurrente, Paralela y Distribuída
- Concurrent, distributed and parallel processing
- 2023 - 2026 🡆 3 academic years
- Single teacher and supervisor of the subject
- Newly implemented subject